| allbits.csv | 2005/02/15 | 2,265,150 | first peel of the raw bits data |
| allbits3.csv | 2005/02/15 | 612,329 | final version.. produces bit sums at every 4th byte. |
| allbits4.csv | 2005/02/15 | 877,601 | uses a dataset of 3 million bytes (~24M random bits) (raw data not included here) spits out a line after every 48 bytes to keep below the 64K datapoint limit of gnumeric (change the value of the $BytesPerLine variable to get this result). |
| bitcount.perl | 2005/02/15 | 984 | the perl script used to do this. |
| bits.bin | 2005/02/15 | 207,249 | |
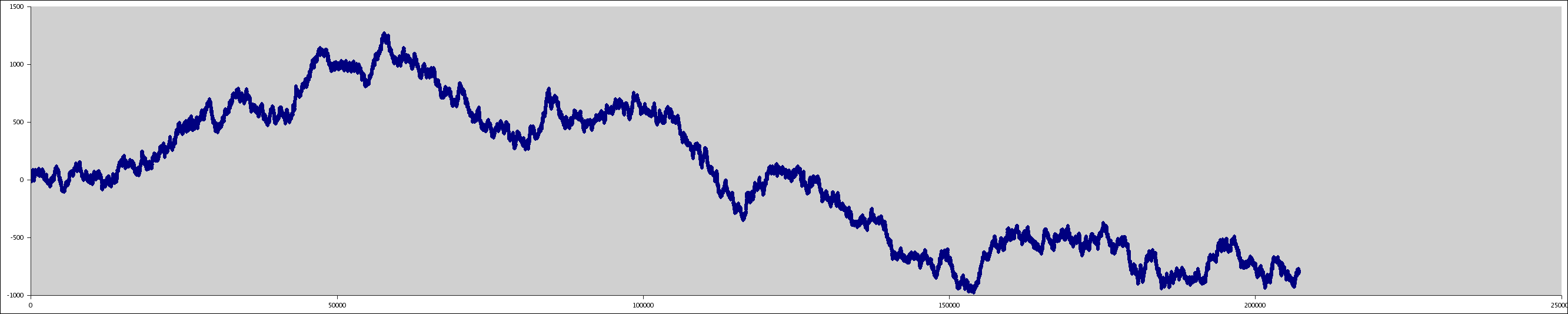
| bits4narrow.png | 2005/02/20 | 75,351 | (990x567) Gnumeric graph of allbits4.csv |
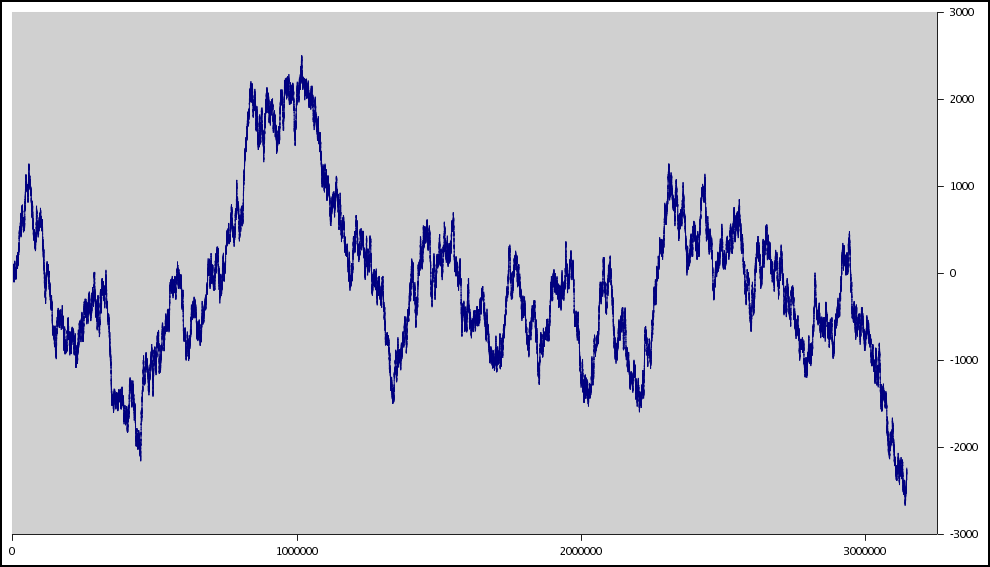
| bits4wide.png | 2005/02/20 | 324,501 | (6485x623) same graph as bits4narrow but widened for more horizontal accuracy. . This is using EXACTLY the same data as bits4narrow.png. Just a different horizontal scale. Note the two very differnt views of the 'spike' around the 1,000,000 byte point |
| rndsum.png | 2005/02/15 | 21,050 | Graphical display of the sums over time |
Bitcounts.perl is the program that I used to generate the data.. (pretty simple);
randsum.png took the data from allbits3.csv and used it to generate a graph.
The program I used to do this was gnumeric ( http://www.gnome.org/projects/gnumeric/ ).
It's essentially a free replacement for Excel. You should be able to do the same using
excel's graphing capability.
Notice how
the data jumps about... This should be generally look roughly the same if I produced the
data from 1 billion pieces of data and reduced the magnification. Notice how you have
occasional peaks and valleys. This is normal for random data.
Yes, I know that the counts are different. I was collecting random data as I
was writing the program. (generating reasonably good and random data
on a computer without a hardware random data generator is actually a bit
of work. Some seriously high-end cryptogrophers have gotten together to
design the one used on Linux (where this was generated) -- /dev/random.
/dev/urandom generates random data much faster (and likely to be 'good enough'
for most applications, but not quite as provably random (it actually
takes the data from /dev/random and uses that to ongoingly seed a pseudo random
number generator)..
Gnumeric doesn't like graphing more than 65000 data points at a time, which is
why I only graphed data points for every 4th byte.
{kind=link}
{kind=link}
{kind=link}